
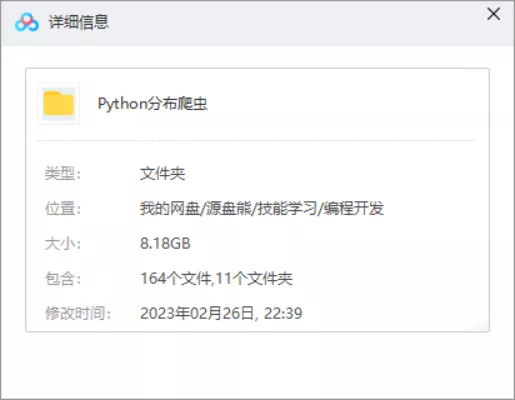
资源名称:Python教程
合集数目:全集
资源类型:技能学习
资源格式:MP4
资源大小:8.18GB
存储方式:百度云网盘
收藏网站:【源盘熊】https://www.z888t.com/
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
截止到 2007 年底,Internet 上网页数量超出 160 亿个,研究表明接近 30%的页面是重复的;动态页面的存在:客户端、服务器端脚本语言的应用使得指向相同 Web 信息的 URL 数量呈指数级增长。
上述特征使得网络爬虫面临一定的困难,主要体现于 Web 信息的巨大容量使得爬虫在给定时间内只能下载少量网页。 Lawrence 和 Giles 的研究表明没有哪个搜索引擎能够索引超出 16%的Internet 上 Web 页面,即使能够提取全部页面,也没有足够的空间来存储……
资源列表:
章节1-爬虫前奏
001.爬虫前奏_什么是网络爬虫.mp4
002.爬虫前奏_HTTP协议介绍.mp4
003.爬虫前奏_抓包工具的使用网络请求.mp4
章节2-网络请求
1 urlopen函数用法.mp4
2 urlretrieve函数用法.mp4
3 参数编码和解码函数.mp4
4 urlparse和urlsplit函数用法.mp4
5 实战-用Request爬取拉勾网职位信息.mp4
6 作业-内涵段子爬虫作业.mp4
7 ProxyHandler实现代理ip.mp4
8 cookie原理和格式详解.mp4
9 实战-爬虫使用cookie模拟登录.mp4
10 实战-爬虫自动登录访问授权页面.mp4
11 cookie信息的加载与保存.mp4
12 requests库的基本使用.mp4
13 requests发送post请求.mp4
14 requests使用代理ip.mp4
15 requests处理cookie信息.mp4
16 requests处理不信任的ssl证书.mp4
章节3-数据解析
1 xpath介绍和工具安装.mp4
2 xpath语法详解.mp4
3 lxml解析html代码和文件.mp4
4 lxml和xpath结合使用详解.mp4
5 实战-豆瓣电影爬虫.mp4
6 实战-电影天堂爬虫之网页分析.mp4
7 实战-电影天堂爬虫之爬取详情页url.mp4
8 实战-电影天堂爬虫之解析详情页.mp4
9 实战-电影天堂爬虫之爬虫完成.mp4
10 作业-腾讯招聘网爬虫作业.mp4
11 bs4库的基本介绍.mp4
12 bs4库的基本使用.mp4
13 bs4库提取数据详解.mp4
14 css常用选择器介绍.mp4
15 select和css选择器提取元素.mp4
16 bs4库拾遗.mp4
17 实战-中国天气网爬虫之页面分析.mp4
18 实战-中国天气网爬虫之华北城市数据爬取.mp4
19 实战-中国天气网爬虫之所有城市数据爬取.mp4
20 实战-中国天气网爬虫之数据可视化.mp4
21 单字符匹配规则.mp4
22 匹配多个字符.mp4
23 常用匹配小案例.mp4
24 开始结束和或语法.mp4
25 转义字符和原生字符串.mp4
26 group分组.mp4
27 re模块常用函数.mp4
28 实战-古诗文网爬虫实战.mp4
29 作业-糗事百科爬虫作业.mp4
章节4-数据储存
1 json字符串介绍.mp4
2 dump成json字符串以及编码问题.mp4
3 load成Python对象.mp4
4 读取csv文件的两种方式.mp4
5 写入csv文件的两种方式.mp4
6 windows下安装MySQL数据库.mp4
7 使用软件和代码连接数据库.mp4
8 使用代码插入数据的两种方式.mp4
9 使用代码查找数据的三种方式.mp4
10 使用代码删除和更新数据.mp4
11 mongodb数据库的安装.mp4
12 mongodb数据库启动和连接.mp4
13 将mongodb制作成服务.mp4
14 mongodb常用概念介绍.mp4
15 mongodb的基本操作命令.mp4
16 python操作mongodb.mp4
章节5-爬虫进阶
1 多线程概念和threading模块介绍.mp4
2 使用Thread类创建多线程.mp4
3 多线程共享全局变量以及锁机制.mp4
4 Lock版生产者和消费者模式.mp4
5 Condition版生产者与消费者模式.mp4
6 Queue线程安全队列讲解.mp4
7 实战-下载表情包之同步爬虫完成.mp4
8 实战-下载表情包之异步爬虫完成.mp4
9 GIL全局解释器锁详解.mp4
10 作业-多线程下载百思不得姐段子爬虫作业.mp4
11 ajax介绍和爬取ajax数据的两种方式.mp4
12 selenium+chromedriver安装和入门.mp4
13 selenium关闭页面和浏览器.mp4
14 selenium定位元素的方法详解.mp4
15 selenium操作表单元素.mp4
16 selenium行为链.mp4
17 selenium操作cookie.mp4
18 selenium的隐式等待和显式等待.mp4
19 selenium打开多窗口和切换窗口.mp4
20 selenium使用代理ip.mp4
21 selenium中的WebElement类补充.mp4
22 实战-selenium完美实现拉勾网列表页之爬虫解析.mp4
23 实战-selenium完美实现拉勾网详情页之爬虫解析.mp4
24 实战-selenium完美实现拉勾网爬虫之跑通流程.mp4
25 实战-selenium完美实现拉勾网爬虫之细节处理.mp4
26 作业-使用selenium实现boss直聘爬虫作业.mp4
27 tesseract库介绍.mp4
28 tesseract在终端下识别图片.mp4
29 tesseract代码识别图片.mp4
30 tesseract处理拉勾网验证码.mp4
31 12306抢票流程分析.mp4
32 登录12306功能完成.mp4
33 购票信息输入功能完成.mp4
34 自动查询余票功能完成.mp4
章节6-Scrapy
1 scrapy框架架构详解.mp4
2 scrapy框架快速入门.mp4
3 实战-糗事百科之爬虫编写.mp4
4 实战-糗事百科之pipeline保存数据.mp4
5 实战-糗事百科之优化数据存储的方式.mp4
6 实战-糗事百科之抓取多个页面.mp4
7 CrawlSpider讲解.mp4
8 实战-CrawlSpider实现微信小程序社区爬虫.mp4
9 Scrapy_Shell的使用.mp4
10 Request和Response对象讲解.mp4
11 实战-scrapy模拟登录某社交网.mp4
12 实战-scrapy模拟登录豆瓣网.mp4
13 实战-自动识别豆瓣网验证码.mp4
14实战-汽车之家宝马5系图片下载爬虫(1).mp4
15 实战-汽车之家宝马5系图片下载爬虫(2).mp4
16 实战-汽车之家宝马5系图片下载爬虫(3).mp4
18 下载器中间件讲解.mp4
19 反爬虫-设置随机请求头.mp4
20 反爬虫-开放ip代理池和独享代理配置.mp4
21实战-攻克BOSS直聘反爬虫之正常爬取.mp4
22 实战-攻克BOSS直聘反爬虫之无限爬取.mp4
23 简书网整站爬虫之页面解析.mp4
24 实战-简书网整站爬虫之保存数据到Mysql.mp4
25 实战-简书网整站爬虫之爬取ajax数据.mp4
26 分布式爬虫介绍.mp4
27 redis介绍.mp4
28 linux下安装redis.mp4
29 windows下redis安装与配置.mp4
30 配置其他机器连接本机redis服务器.mp4
31 redis的字符串操作.mp4
32 redis的列表操作.mp4
33 redis的集合操作.mp4
34 redis的哈希操作.mp4
36 实战-房天下全国658城市房源信息抓取(2).mp4
37 实战-房天下全国658城市房源信息抓取(3).mp4
38 实战-房天下全国658城市房源信息抓取(4).mp4
39 实战-房天下全国658城市房源信息抓取(5).mp4
40 实战-房天下全国658城市房源信息抓取(6).mp4
41 实战-房天下全国658城市房源信息抓取(7).mp4
实战-房天下全国658城市房源信息抓取(1).mp4
实战-房天下全国658城市房源信息抓取(7).mp4
1.本站所有资源版权均属于原作者或出版社方所有,如侵权原作者或发行商版权,请联系客服,我们将立即删除。
2.资源侵权删帖联系,资源失效等请联系客服QQ383674314,微信yyzz369789



